
Prometheus - Scale prometheus cho Kubernetes
Scale là một thứ cốt yếu phải có trong mỗi hệ thống. Ở thời đại công nghệ thông tin bùng nổ, traffic và dữ liệu tăng nhanh 1 cách không thể kiểm soát thì tính scale ở hệ thống phải là 1 phần tất yếu. Và hệ thống monitoring cũng thế, hôm nay mình sẽ giới thiệu qua về Prometheus - monitoring cho micro-services trong Kubernetes và làm thế nào để scale prometheus monitor cho kubernetes khi lượng data, metrics monitor đang tăng nhanh.
Prometheus là một công cụ open-source thu thập metrics time-series. Là một công cụ monitor phổ biến được dùng để lấy metrics về hệ thống, ứng dụng ... và dễ dùng, tích hợp đơn giản vào trong kubernetes hoặc các hệ thống khác.
Kubernetes, thường ở các hệ thống đang setup tích hợp prometheus để monitor về cluster kubernetes của mình, đặc biệt là gần đây có công cụ prometheus-operator giúp quản lý về ServiceMonitor các ứng dụng chạy trong kubernetes, cung cấp khả năng quản lý nhiều prometheus cùng chạy trong 1 cluster.
Và prometheus khả năng của nó là giới hạn. Ví dụ 1 big-VM chạy prometheus có những giới hạn về Memory, Cpu và disk storage để lưu trữ metrics hệ thống, hoặc trường hợp bạn có trên 2 kubernetes cluster thì giải pháp là Prometheus Federation là một giải pháp đơn giản cho scaling, nơi mà một master prometheus có thể thu thập metrics của nhiều prometheus trong nhiều cụm kubernetes cluster. Và một giải pháp nữa giúp prometheus stable hơn khi gặp issue là giải pháp lưu trữ ở một cụm storage ngoài con master prometheus federate được đề cập ở trên.
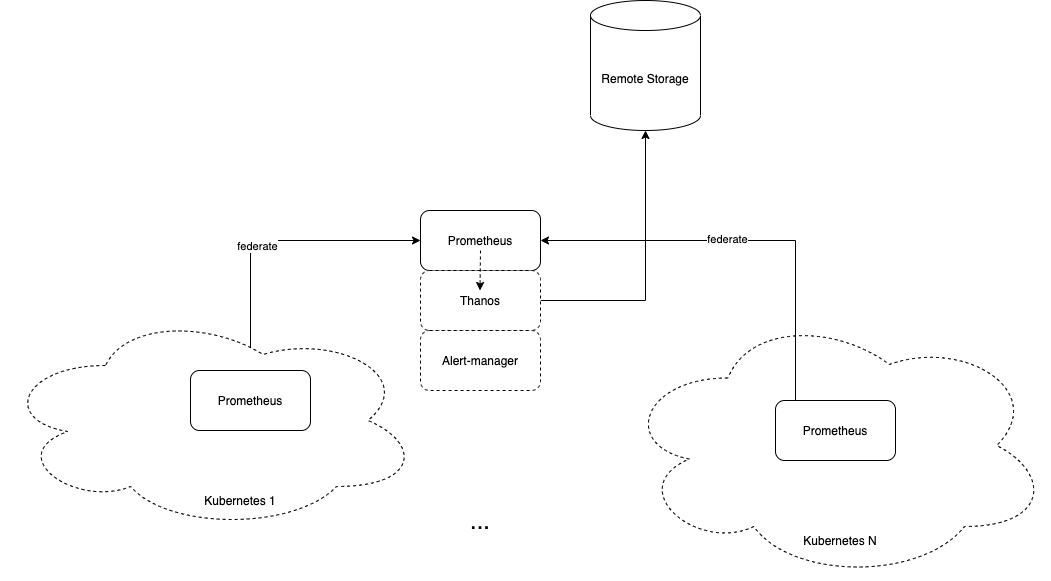
Cách cấu hình rất đơn giản:
scrape_configs:
- job_name: federated_prometheus
honor_labels: true
metrics_path: /federate
params:
match[]:
- '{job=~”^job:.*”}'
static_configs:
- targets:
- prometheus-slave1:9090
- prometheus-slave2:9090match[] param như đoạn cấu hình trên sẽ lấy tất cả metrics trong các jobs đang có của prometheus-slave1 và 2.
Khi cấu hình federate về các bạn có thể cấu hình retention 2h hoặc 2d tuỳ khả năng lưu trữ các bạn có. Song song đó các bạn có thể cấu hình thanos để snapshot hoặc backup các metrics đã retention lên remote storage mà thanos support: s3, glusterFS, gcp ...
Monitoring, metrics là một phần không thể thiếu của mỗi devops team. Bài này mình giới thiệu về cách cấu hình cho chức năng federation của promtheus và giới thiệu sơ về thanos, sẽ có 1 bài giới thiệu về thanos và cấu hình thanos, chờ nhé. hihi.


